Mining for Cancer Insights
Cheryl Cropp ventures away from the bench to dig into cancer data.

In 2007, Cheryl Cropp, Ph.D., visited the NIH campus in Bethesda, Md. to present her research poster
Back in 2007, Cheryl Cropp, Ph.D., was studying pharmacogenomics at the University of California, San Francisco, when she saw an ad that caught her eye: “Join graduate students from across the U.S. at the NIH National Graduate Student Research Festival.” After applying for the annual two-day event held on the main NIH campus in Bethesda, Md., she was selected to present a poster about her graduate research on a potential genetic basis for varying efficacy of the drug acyclovir in treating herpes virus hepatitis.
The conference catalyzed Cropp’s career, as it was then she met Joan Bailey-Wilson, Ph.D., a senior investigator in the National Human Genome Research Institute (NHGRI), and became aware of opportunities at the NIH to follow her passion for data analysis.

Dr. Cropp and her mentor, Joan Bailey-Wilson, Ph.D., plan next steps in the genetic analysis of a family with several members exhibiting prostate cancer
“After my graduate studies, I wanted to focus my research on understanding how a particular genetic background or the presence of specific genetic markers may predispose populations to certain diseases,” Cropp says. “However, this type of analysis is often compared to looking for a needle in a haystack—not only because of the immense amount of data that needs to be screened for these types of studies, but also because genetic screens, like all scientific analyses, are prone to result in ‘false positives’—results that suggest something is there, when in fact it is not.”
Now a post-doctoral researcher in the IRP, Cropp uses a powerful suite of statistical tools to ensure data from large genetic screens is accurate and meaningful. The amount of information gathered can be staggering, which is where her analytical skills come into play. In order for scientists and clinicians to determine next steps—whether a more detailed genetic analysis or pharmacotherapy—such “big data” must be examined closely.

Cropp leads a group discussion
“In a genome-wide study to find genes associated with a particular cancer, you might expect to find 800,000 or so markers, or areas of the genome that may play a role in the development of that cancer,” Cropp explains. “Of these, 800 or so may actually be significant, but, once you account for multiple testing and other statistical elements, you could find yourself down to only 30 areas of interest.” Instead of a haystack, the researcher then has 30 neatly arranged pieces of straw, perhaps one of which will contain the proverbial needle.
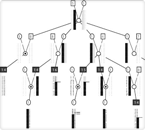
A pedigree suggestive of maternal inheritance of prostate cancer, with a single patient who likely has prostate cancer for a different reason
Driven by her family history of prostate cancer and desire to find susceptible targets for her pharmacology training, Cropp began looking at the genetic epidemiology of the disease through collaboration with a Finnish research group. Prostate cancer is the most common fatal cancer in men over age 75, yet the genetic basis of this disease has not been well characterized. The Finnish group contacted 69 families who had all been severely affected by prostate cancer—each with at least three confirmed cases—and who agreed to provide a blood sample for genetic analysis. The advantage of doing this research in Finland is that the selected families are from a ‘founder population’—a group of people who had a small set of founders of the modern population and who, due to terrain or harsh conditions, became isolated from the world’s population and therefore tend to have a very similar genetic pool.

The team (Left to right, front to back): Cristina Justice, Alexa Sorant, Cheryl Cropp, Yoonhee Kim; Alexander Wilson, Heejong Sung, Claire Simpson; Silke Szymczak, Mera Tilley, Bhoom Suktitipat; Qing Li, Joan Bailey-Wilson, and Brian Perry
With DNA from each individual, Cropp and her collaborators began a genome-wide linkage study to find conserved areas of the genome that hint at a role in prostate cancer. After lengthy and complex data analysis, the team found what they were looking for: three areas that appear to be highly conserved in prostate cancer—a newly discovered area on chromosome 2, a known area on chromosome 17, and confirmation of a well-characterized gene-free area on chromosome 8. This “gene desert”—an area of the genome that contains no known genes, but appears to play a critical role in a number of cancers—is a paradox to researchers, highlighting how far we have to go to fully understand the genetic basis of cancer. New studies suggest a possible role in prostate cancer of non-coding RNA’s in the 8q24 region, but much work remains to be done.

Cropp at the NIH-Bayview campus in Baltimore, Md.
Cropp and her colleagues continue “mining” the Finnish prostate cancer data, peeling away layer after layer to reveal ever-increasing insight into the disease, a process that she describes as immensely satisfying. Having found her life’s passion, Cropp also approaches her work pragmatically. She points out that while genome screening technologies are becoming more widely available at lower costs, the exponentially greater amount of data generated as a result of innovations keeps it challenging and costly to both analyze and store the information.
Bringing the genetic basis of complex diseases such as cancer fully into the light will require continued investment in young researchers like Cropp—the next generation of genetic epidemiologists, pharmacogenomic scientists, and biomedical statisticians—talented individuals inspired to separate the wheat from the chaff in the quest for human health.
Cheryl Cropp, Ph.D., is a post-doctoral researcher in the laboratory of Joan Bailey-Wilson, Ph.D., in the Statistical Genetics Section of the Inherited Disease Research Branch at the National Human Genome Research Institute (NHGRI).
This page was last updated on Wednesday, May 24, 2023